Architecting for Performance and Scalability
For lower volume environments it may be practical to run your email infrastructure on a single KumoMTA instance, especially in a virtualized environment where single-node fault tolerance is relatively high.
In high-volume environments the deployment architecture can have a significant impact on the performance and scalability of your KumoMTA installation.
The following areas should be considered when planning a high-volume KumoMTA installation:
CPU Architecture
KumoMTA is available for both Intel and ARM architectures. While the individual node performance on ARM will be lower than on Intel, horizontal scaling makes it possible to achieve a better price/performance ratio.
Horizontal Scaling
While KumoMTA can be deployed on very large servers with excellent results (in excess of 20 million messages per hour on a single node), vertical scaling is not as cost effective as horizontal scaling and can result in significant capacity loss in the event of a server failure. We recommend targeting a throughput of somewhere between 4-6 million messages per hour per node in your deployment.
Dynamic Cluster Sizing
In most sending environment there is a cyclical nature to sending volumes that can vary on the time of day, day of week, and even month of the year. In cyclical environment it can be very cost effective to scale the size of your cluster up and down based on these cycles, especially in public cloud environments.
KumoMTA does not automatically perform cluster scaling as our users deploy in a wide variety of ways, but we do provide tools to help users perform the scaling using their tool of choice. See the Scaling page in the Clustering chapter of the User Guide for more information.
Hardware Planning
When planning for hardware in a performance environment you should plan on testing multiple options where practical (such as in a public cloud environment). In our testing we have identified that a good starting point is servers with 16 cores and 32GB of RAM. Disk IOPS and throughput can be a bottleneck in some environments so it is important to calculate disk needs based on your average message size and desired throughput. Disk capacity is calculated based on average message size and expected queue depth.
The following chart shows internal KumoMTA testing and should provide a rough estimate of hardware deployments:
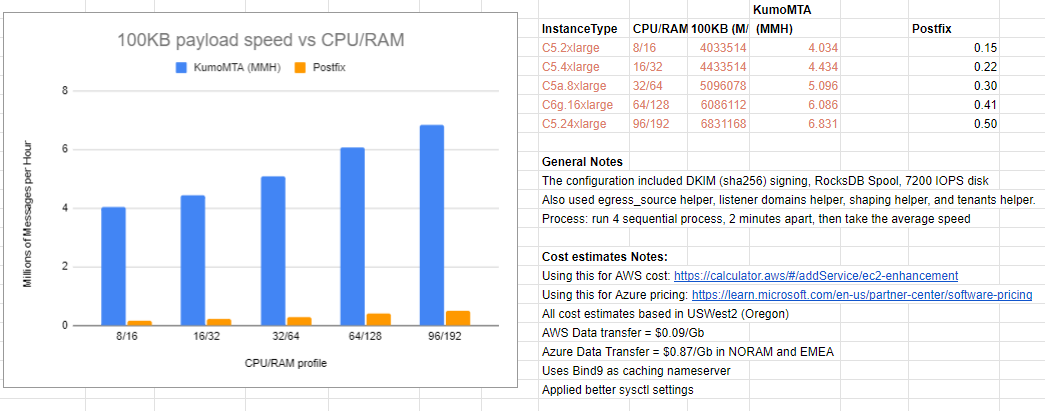
For more information on hardware see this blog post.
Disk Performance
When planning storage, especially on physical hardware, it is important to consider the different I/O that runs in parallel on an active MTA. These I/O sets should ideally reside on separate disks:
1) Spool - KumoMTA will be continuously reading and writing from/to the spool disk. By default KumoMTA will place its spool under /var/spool/kumomta and this location should be mounted to a separate disk (or at least a separate partition).
2) Logs - KumoMTA will continuously write logs, and it should be noted that there is no log purging provided by KumoMTA. By default logs will be written under /var/log/kumomta which should be mounted on a separate disk (or a least a separate partition). To prevent running out of disk space you will need to implement log rotation and deletion based on your needs for data retention.
3) Other IO - While KumoMTA will perform the majority of its I/O on the spool and log directories, a separate root partition is recommended to help isolate the general I/O from the spool and log I/O.
Network Performance
An MTA cannot relay messages faster than it can move data across the network, and in extremely high-volume environments this can introduce significant network bandwidth needs.
Modern 10Gbps networking is recommended, and WAN throughput needs should be calculated based on average message size times desired messages per hour (with generous headroom).
Keep in mind that every message you relay consumes bandwidth twice on a given MTA: once as the message arrives and once as it is relayed out, so when considering bandwidth at the server NIC you should look at double the desired maximum message rate. In some cases it can be beneficial to separate out internal and external traffic to separate NICs where one interface is used for incoming LAN traffic from message generators and another interface is used for outbound relay to the WAN.
Separation of Machine Roles
When planning a high-performance architecture for KumoMTA one key principle is to ensure that KumoMTA nodes are only responsible for running KumoMTA. This means that all other daemons and executables should be hosted on separate systems.
Some of the components that should be offloaded to their own servers include:
- The TSA Daemon - While it is acceptable to operate the TSA daemon on the same node as KumoMTA in a single-node environment, separating out the TSA daemon to its own node(s) is preferred for larger deployments.
- Redis - Redis is used in multi-node environments for common throttles and counters and should not run on the same hardware as individual nodes.
- Injectors - A common architecture in many sending environments is to run message generators on the MTA nodes. This approach can lead to resource contention between the generators and the KumoMTA daemon and should be avoided.
- Log Processors - Another common architecture choice is to run log processors locally on the MTA nodes, with the processor reading the logs and pushing the data to a destination of choice. We recommend configuring KumoMTA either with log hooks to deliver data via HTTP/AMQP/Kafka, or to operate the minimum tooling necessary to move log files to a separate system for processing. Note that any log processing done locally will potentially lead to resource contention and can take disk IOPS away from the KumoMTA daemon.
- DNS - While we do recommend running a local caching Bind 9 service to ensure DNS performance, you do not need to run it on your MTA hardware. KumoMTA has its own resolver and caching in-process, DNS should be on its own server local to the KumoMTA nodes.